The Master Theorem For Time Complexity
In this article, we will model the time complexity of divide and conquer using mathematical methods, analyze its asymptotic properties, and provide three methods of calculation.
When we navigate through the ocean of divide and conquer, there's a question that must be addressed—how is the time complexity of divide and conquer algorithms calculated?
From Divide and Conquer to Recurrence Relation
Divide and conquer involves breaking down a large problem into smaller subproblems and then merging the solutions of these subproblems to obtain the solution to the original problem. Recurrence relation is a mathematical way of modeling the time cost of this process.
Starting with a concrete example makes it easier to understand. Taking merge sort as an example, let represent the time complexity of the original problem, where is the size of the input data. In the first split, the original data is divided into two equal parts, each of size . Then, recursive calls to merge sort are made on these two parts, and the time complexity of this part is . Finally, the two sorted subarrays are merged, requiring a time complexity of .
Based on the analysis above, we can write the recurrence relation for merge sort as follows:
It can be imagined that for any divide and conquer algorithm, its time complexity can be expressed as a recurrence relation. The right-hand side of the recurrence relation usually consists of two parts: the total cost of the divided subproblems and the total cost of dividing and merging subproblems. The first part remains a function of , while the second part represents the actual asymptotic complexity.
Having a recurrence relation is not sufficient to determine the exact time complexity of the algorithm. We need to further calculate the actual solution .
Substitution Method
The first method for solving recurrence relations is called the substitution method. We need to guess the form of the solution first and then use mathematical induction to prove that the guess is correct.
For Equation (1), let's assume that our guess for the solution is . If we remove the asymptotic notation, this equation is equivalent to , where is any positive constant.
According to mathematical induction, we first need to establish that the guess holds for small values of . When , according to Equation (1), , where is some constant greater than 0. According to the guess, we hope , but no matter how we choose , this equation cannot hold because is always greater than 0. The mathematical induction fails before it even starts.
However, there is no need to worry; this is just a special case caused by . We can place the initial state of mathematical induction at without affecting the results of mathematical induction. We are only interested in the asymptotic properties of when is sufficiently large, not in the initial stage.
Now, let , then . We hope that holds. Simplifying, we get . Since and are constants, such exists, and the initial condition holds.
Next, mathematical induction assumes that the solution holds at , i.e., . Then we prove that also holds.
Substituting into Equation (1), we get
Where the last line's inequality requires , obviously such exists, so the proof is complete.
Thus, we have proved that is the solution to the recurrence relation (1). However, this is not the end; this asymptotic notation is not a tight bound. Can we further guess that holds? This is indeed a good idea. So, as we proceed, as long as we can prove that holds, we can obtain the tight bound mentioned above. Removing the asymptotic notation, this equation is equivalent to . Using mathematical induction again, confirming that this holds in the initial stage, and then assuming that the solution holds at , we can derive that the solution holds at . Therefore, the proof is complete. Since the proof steps are almost identical to those just mentioned, we will not elaborate on them, and you can try it yourself.
The substitution method relies on accurate guesses, which can be impractical. Therefore, in practice, a more common approach is to find a guess using other methods and then use the substitution method to verify the guess. The recursive tree method we will introduce next provides this possibility.
Recursive Tree
Expanding the recurrence relation layer by layer directly yields a tree structure. For example, let's take as an example and see how to draw its recursive tree.
Expanding the first layer, we draw three child nodes under the root node.
Here, represents the cost of decomposition and merging at this layer, which corresponds to the part represented by in the recurrence relation.
Next, further expand to the second layer.
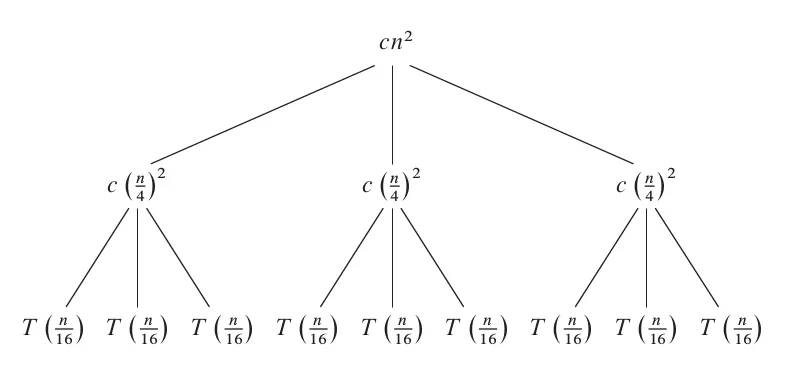
Here, the cost of each node in the first layer is still , still corresponding to the part represented by in the recurrence relation, but the data size has changed from to .
Continue expanding in this way until the leaf nodes.
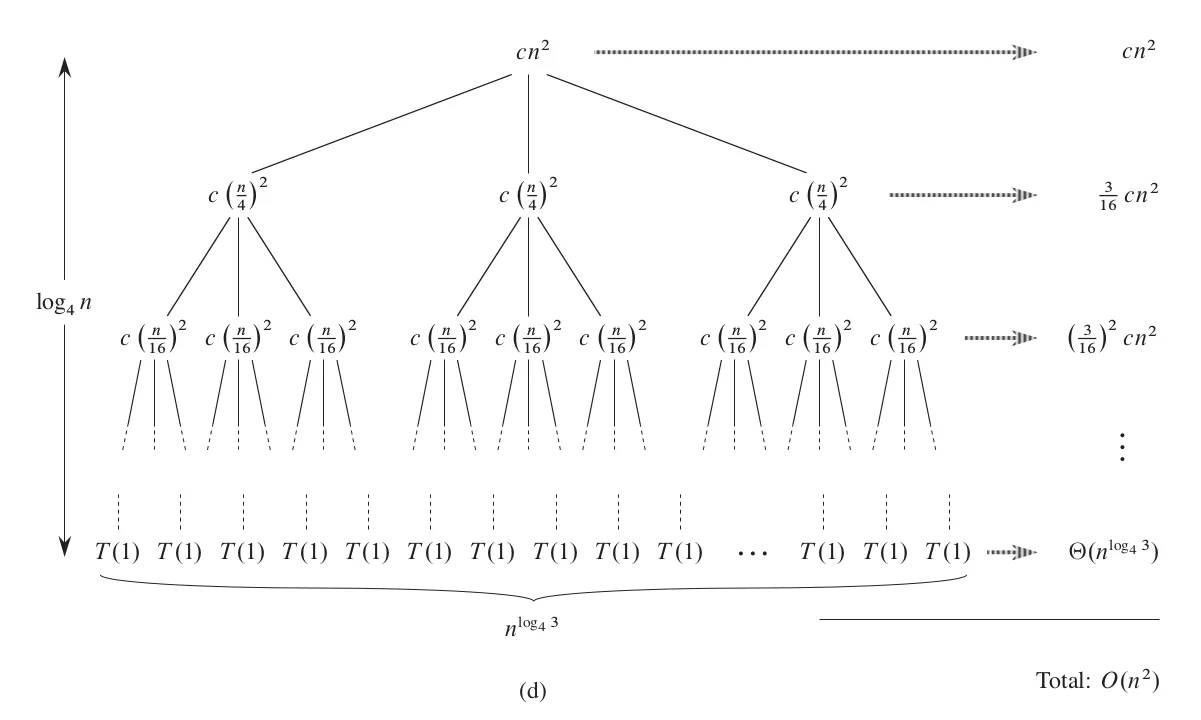
This completes a complete recursive tree. The data size of each layer is reduced to one-fourth of the previous one, until the data size of the leaf node is 1, so the total number of layers is . The rightmost side of the figure calculates the total cost of all nodes in each layer, and the calculation is simple: multiply the cost of a single node by the number of nodes in that layer. In the last layer, the cost of a single node is a constant, and the number of nodes is , and we denote the total cost as .
Next, we just need to add up the costs of all nodes to obtain the solution to the recurrence relation.
Here, in the third line, we made a simplification by replacing a finite geometric series with an infinite geometric series. Although the total size has increased, this infinite decreasing geometric series has a limit, so this replacement can simplify the derivation process. The second term in the fifth line is a lower-order term relative to the first term, so it is discarded, resulting in the final result.
Similar to before, we have only proven the upper bound of the recurrence relation. Naturally, we want to try whether it can also be proven as a lower bound. In the above equation, each term in the summation contains , and each term is positive, so obviously holds. Therefore, the solution to the recurrence relation is .
In this example, we directly calculated the solution to the recurrence relation using the recursive tree method. Of course, we can use the substitution method to verify whether this solution is correct. In some cases, it may be slightly difficult to calculate the exact solution using the recursive tree method, but it does not prevent us from making a reasonable guess and then further verifying this guess using the substitution method.
Master Theorem
Both the substitution method and the recursion tree method have their drawbacks. The former requires an accurate guess, while the latter involves drawing a recursion tree and deriving results. If you derive too much, you may find that the forms of most recursive solutions seem to be the same. From the derivation process above, it can be observed that the final solution depends entirely on the sum of costs in the middle layers and has nothing to do with the leaf layer because the latter is a lower-order term. In other recursion trees, the final solution may depend entirely on the cost of the leaf layer, unrelated to the middle layers. Therefore, we may be able to classify recursive formulas and directly write out the final solution according to some rules. This is the idea behind the master theorem.
When the divide-and-conquer method evenly splits the data each time, the recursive formula generally has the following form.
where is a positive integer representing the number of subproblems when dividing each time, is an integer greater than 1 representing the reduction factor in problem size each time, and is an asymptotically positive function representing the cost of dividing and merging.
To find a unified solution applicable to any , , and , we still need to use the recursion tree to calculate the costs of all intermediate and leaf nodes and try to derive a simple result.
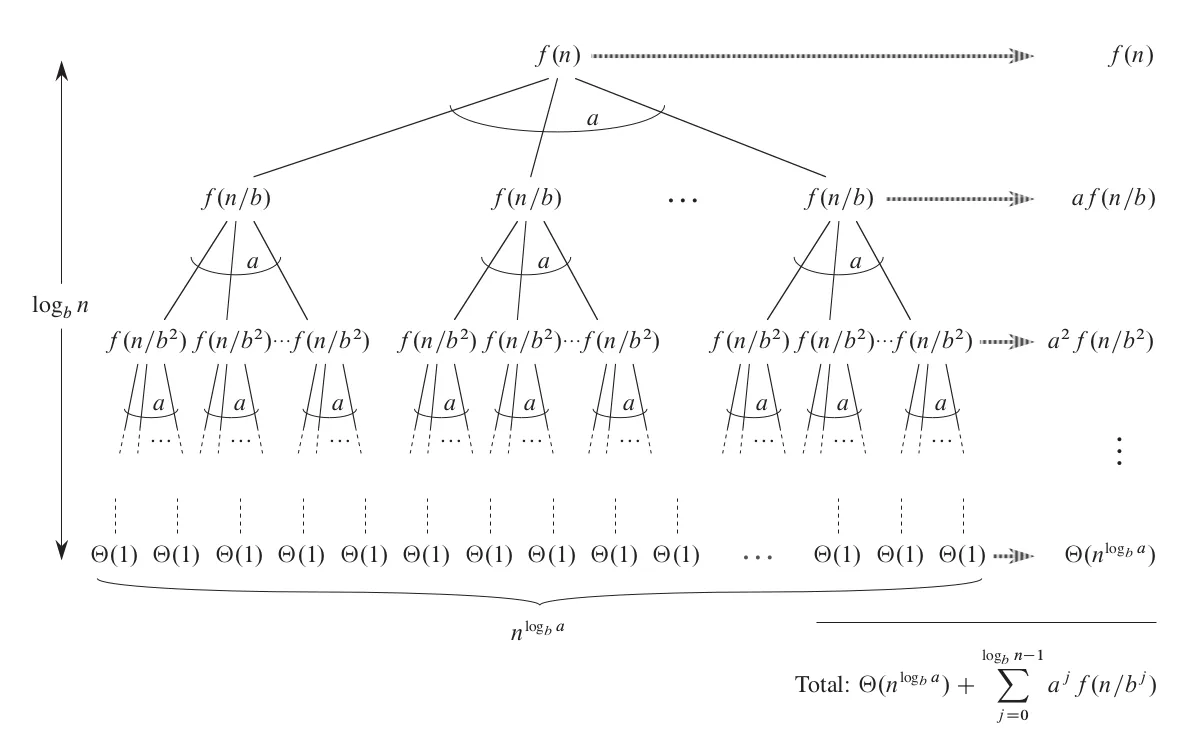
From the graph, we can see that the total cost of all nodes is . Further derivation requires a breakthrough idea, and I don't know how the original researchers discovered the following pattern, but it is indeed magical.
Researchers found that the relationship between and determines the final simplified form of . Define
Now let's analyze three cases.
-
If is larger, we can assume that there exists a constant such that . Substituting this into the summation formula, it can be simplified to .
-
If both are equally large, directly substitute into equation (3) and simplify to get .
-
If is larger and, for some constant , for all sufficiently large , holds, then it can be deduced that .
Here, the complete proof process is not provided, partly because I don't want to make it too long, and secondly, I feel that these proofs are somewhat cumbersome and not very meaningful. Interested students can refer to the original book.
Substituting the functions for these three cases into the complete solution, we get:
-
For case 1:
-
For case 2:
-
For case 3:
Now, for any recursive formula, we only need to determine which case it belongs to and directly substitute into the corresponding formula. To facilitate understanding, let's go through a few examples.
Example 1:
For this recursive formula, we have , , . Since is asymptotically smaller than , it can be applied to the first case of the master theorem, and the solution is .
Example 2:
For this formula, , , . Since , which is exactly equal to , it can be applied to the second case of the master theorem, and the solution is .
Example 3:
For this formula, , , . Since , and is asymptotically larger than , it should consider the third case of the master theorem. However, we need to check if the additional condition holds: for some constant and all sufficiently large , holds. Substituting , , and into the inequality, we get
When , this inequality always holds, and the additional condition is satisfied. Therefore, it can be applied to the third case of the master theorem, and the solution is .
Example 4:
For this formula, , , . Since , and is asymptotically larger than , it should consider the third case of the master theorem. Substituting , , and into the inequality, we get
When , this inequality always holds. However, the additional condition requires , so this case cannot be applied to the third case of the master theorem. In other words, not all recursive formulas of the form can be solved using the master theorem; there is a gap between cases two and three. In such cases, we can only use the recursion tree method. Students can try it, and the result will be .
After going through these four examples, have you mastered the master theorem? If you have any questions, please leave a comment, and I will reply as soon as possible.
The study of algorithms is endless, and the calculation of time complexity is fundamental and should not be underestimated.
Details
Careful readers may notice that in the fourth case mentioned above, although grows asymptotically faster than , it is not asymptotically greater in the polynomial sense because there is no such that holds. On the contrary, holds for any . So, in fact, this case does not need to be judged for regular conditions to draw conclusions in advance. However, in the third case in the previous text, I did not emphasize asymptotic greater in the polynomial sense, not because I forgot to write it, but because this condition is not needed at all.
For any recurrence relation that fits the master theorem format, if it satisfies the regular conditions in case three, then it must satisfy ." The specific proof details can be found in this answer on StackExchange, and are not detailed here.
Although regular conditions can imply , the reverse is not true. We can construct the following function:
Here, , , and holds for any . However, when applying the regular condition:
For any , the right side must be . However, the left side, when is large enough, must be greater than . Therefore, this equation cannot hold, and the regular condition is not satisfied.
Reference
These cases are from the Wikipedia entry on Master theorem.